CompatibL continues to leverage machine learning to introduce new methods of addressing complex problems for its capital markets clients. In this article, we review recent machine learning use cases in capital markets and share advice gained from CompatibL’s experience of developing Autoencoder Market Models for Interest Rates on how to address the key challenges and implement the technology successfully.
Machine Learning Use Cases in Capital Markets Today
Machine learning models are used in many areas of capital markets. While machine learning was initially used by hedge funds for improved alpha generation, more recently the technology has seen many more applications in trading and risk management.
Alexander Sokol, CompatibL’s Founder and Head of Quant Research:
Machine learning is a transformative new technology that drives innovation in many areas of capital markets. It has the potential to become the market standard in financial product valuation and risk management before the end of the decade.
On a broader scale, machine learning models today are commonly used in the areas of investment management, trading, risk management, and credit decisions. They can be used to identify patterns in large data sets, forecast market movements, and help identify opportunities for trading. They are also used to develop automated trading systems, detect fraudulent activities, and help improve portfolio performance.
The invention of variational autoencoders (VAEs) revolutionized many areas of machine learning, from image processing to natural language recognition. Alexander Sokol believes that it holds the same promise for interest rate modeling and can be applied to meet capital markets challenges more efficiently than traditional approaches.
Techniques that have been developed for other areas of machine learning unrelated to the financial industry are now being successfully applied in quant finance. Alexander mentions a recent example of this “cross pollination” between completely different fields, namely the use of speech recognition technology for order book analysis, in an interview with QuantMinds.
Some interesting use cases of machine learning in finance were also discussed at Applied Machine Learning Days 2022. These include using machine learning for new developments in the areas of financial decision-making and time series analysis, addressing the challenges of low signal-to-noise ratio in time series data collected from the financial market, the overfitting problem with nonstationary data, and a high degree of correlation across instruments in the market.
The speakers at Applied Machine Learning Days 2022 pointed out that applying machine learning to finance, so-called financial machine learning, is different than applying it in many other disciplines. Data from financial markets is very noisy, making it difficult to predict the future (a low signal-to-noise ratio). Due to the frequent nonstationary behavior of markets, models need to be able to quickly adapt to regime shifts in order to react appropriately. Frequently, the data that is most insightful may not always be easily available and can be quite sparse (short histories).
The speakers touch on the fact that when applying machine learning models to finance, model developers should bear in mind the following.
- The predictive performance of supervised learning should not be the primary focus when designing trading strategies.
- Financial markets are mostly rational, and learning patterns or forecasting the future efficiently is difficult.
- It is important to have good knowledge about both the domain (e.g., finance, microeconomics) and the methods (e.g., statistics, machine learning, artificial intelligence). For instance, CompatibL hires and trains quants who have both exceptional software engineering skills and in-depth knowledge of math and quant models.
- During the training of machine learning models, you should consider that trading will affect future prices and that using only historical data for training can be greatly misleading.
- Deploying machine learning models at scale in production is far from straightforward.
Other research on machine learning methods in finance, which we quote below, features detailed use cases and provides a classification of machine learning applications based on three archetypes.
1. Construction of superior and novel measures
Studies of this archetype use machine learning to extract information from high-dimensional, unconventional data such as text, images, or videos and construct a numerical measure of an economic variable.
| Category | Subcategory | Measures |
| Measures of Sentiment | Stocks |
|
| Sovereign Debt |
|
|
| Products |
|
|
| Measures of Corporate Executives’ Characteristics | Personality Traits |
|
| Beliefs |
|
|
| Emotions |
|
|
| Actions and Working Patterns |
|
|
| Quality |
|
|
| Looks |
|
|
| Measures of Firm Characteristics | Financial Characteristics and Risk Exposures |
|
| Corporate Culture |
|
|
| Connectedness |
|
2. Construction of superior and novel measures
Studies of the second archetype of machine learning applications in finance apply machine learning to reduce prediction error in economic prediction problems.
| Category | Subcategory | Measures |
| Prediction of Asset Prices and Trading Mechanisms | Equities |
|
| Bonds |
|
|
| Foreign Exchange |
|
|
| Derivatives |
|
|
| General Financial Claims |
|
|
| Investors |
|
|
| Market Microstructure |
|
|
| Prediction of Credit Risk | Consumer Credit Risk |
|
| Real Estate Credit Risk |
|
|
| Corporate Credit Risk |
|
|
| Prediction of Firm Outcomes and Financial Policy | Financial Outcomes |
|
| Corporate Misconduct |
|
|
| Startup’s Success |
|
3. Extension of the existing econometric toolset
Studies of the third archetype of machine learning applications extend the existing econometric toolset.
| Category | Subcategory | Measures |
| Causal Machine Learning | Instrumental Variable Regression |
|
| Causal–Tree Based Methods and Applications |
|
|
| Other Causal Machine Learning |
|
|
| Special Applications |
|
|
Source: Machine Learning Methods in Finance: Recent Applications and Prospects
Another real-life example of how you can take something in machine learning that was developed for one purpose and adapt it for a totally different purpose comes from CompatibL’s own latest innovation.
We recently developed a new category of machine learning-based quant models, which we call Autoencoder Market Models (AEMM). To do this we adopted a technique from a completely different area. This technique was originally used for image recognition, image analysis, and even image modification (where you can, for example, add a smile to someone’s face). We have used it to analyze how the yield curve can change and to model how it could behave in the future.
This innovation is not limited to interest rates, as the use of autoencoders was not previously attempted in models for any other asset class; CompatibL is thus actively working to extend the autoencoder market model approach to other asset classes with complex, high dimensional market data represented by curves and surfaces, including credit and commodities.
If the trend continues, techniques developed for other areas of machine learning that have nothing to do with the financial industry may have similar successful applications to quant finance.
But the adoption of machine learning in highly regulated industries presents unique challenges developers need to address before the technology can be successfully approved and implemented.
What Challenges Do Developers of Machine Learning Models Meet?
The main challenge to developers of machine learning models is explainability. In other words, the developers must ensure that the model is not perceived as a black box and that both regulators and auditors understand exactly what it does and what can go wrong, which is key to model adoption.
For example, in a recent article, Deloitte discusses the use of Explainable AI (XAI), which allows banks to better understand the decisions made by their AI algorithms by providing line-by-line explanations of each decision. The benefits of better explainability are more accurate risk-based decisions, improved customer experience, and better compliance with regulations. However, it comes with some challenges that banks must expect to face when implementing XAI, such as data complexity, computing resource constraints, and lack of trust in the technology.
Some academics and practitioners also highlight accuracy as an important factor in developing trustworthy AI-based systems. AI systems may produce errors, can exhibit bias, may be sensitive to noise in the data, and often lack technical and judicial transparency, resulting in a reduction in trust and challenges in their adoption.
A variety of machine learning models are being applied to financial prediction problems, but there are several things to consider when deciding on using these models. These include the focus on predictive performance, acknowledging the rationality of financial markets, understanding the domain (e.g., finance, microeconomics) and the methods (e.g., statistics, machine learning, artificial intelligence), taking account of the trading effect on prices during training (e.g., reflexivity, or how trading affects the future price path), and ensuring the successful deployment of machine learning models in production when deploying at scale.
According to a 2022 survey by the Bank of England, the increase in machine learning adoption also poses the following set of challenges:
- The greatest challenge to machine learning adoption and deployment is legacy systems
- The next highest ranked challenge is the difficulty integrating machine learning into business processes
- A lack of clarity within existing regulations also constrains adoption
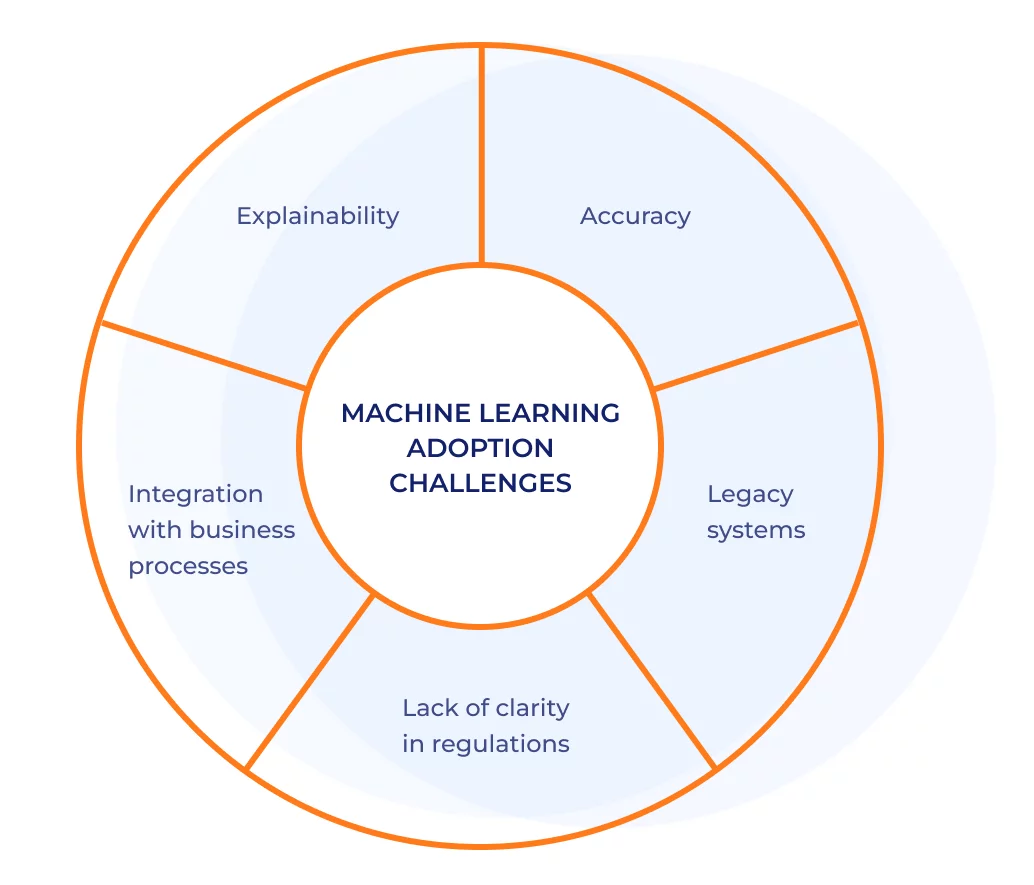
In summary, AI and machine learning have greatly impacted the field of finance, but incorporating machine learning solutions has its challenges. These include issues with data quality and availability, model complexity and explainability, and adapting business processes.
CompatibL thought deeply about these challenges when developing its new models.
How Did CompatibL Address the Challenges in Developing Autoencoder Market Models for Interest Rates?
In the autoencoder-based models developed at CompatibL, the machine learning algorithm is only used in a very limited way. It is intentionally limited to constrain what it does. In this way the developers can see exactly what input it takes in and what output it produces. Then, before using it further, they can analyze the output and ensure that all the requirements from the regulators and auditors required to approve this model are met.
Alexander Sokol:
It was our decision to use autoencoders only for the part of the model that affects curve shapes, while leaving other aspects of the model’s classical specification untouched. We hope that this approach of conservative use of machine learning to improve a single aspect of the model specification in a transparent and explainable way without making radical changes to the model will facilitate the adoption of Autoencoder Market Models by practitioners.
For example, for Autoencoder Market Models, machine learning is only used to create a mapping between the yield curve shapes and model state variables. The training process relies on decades of historical data and can be run periodically (e.g., quarterly), with its results carefully examined before they are used in production.
The accuracy of the resulting mapping can be evaluated and compared with classical methods, such as Nelson–Siegel, or previous versions of the VAE, using a rigorous process based on measuring the curve reconstruction error over the historical dataset.
Ultimately, having a model that is built from simple-to-understand parts, each of which can be validated independently, is key to both the adoption of the model by the practitioner community and receiving approval from the regulators.
How to Adopt a Machine Learning Model
Let us start by showing how traditional models work, in order to better understand how to adopt a machine learning-based one.
Traditional models are based on equations. Sometimes these are stochastic differential equations (SDE), e.g., they have a parametric basis or involve a function used to fit market data.
Usually, these equations are developed based on two properties:


For example, there is a function, called the Nelson–Siegel basis function, for fitting the yield curve (the term structure of interest rates) to a set of exponents. Why is it popular? Because it is simple (it only uses a few parameters), and it is easy to work with.
With machine learning, these equations are replaced with models trained using historical data to optimally represent the historical curves. This approach is better simply because these models are specifically trained to do exactly what they are supposed to do, as opposed to coming up with a formula and then just using it without testing how it performs relative to all the other options.
So, machine learning models are generally adopted by replacing some of these parametric forms or equations with neural networks. These neural networks are trained using historical data, e.g., market data, to do the job those parametric equations were previously doing, but, hopefully, to do it better.
Download the Paper on Autoencoder Market Models for Interest Rates
Alexander Sokol’s working paper on Autoencoder Market Models introduces four types of autoencoder market models, developed by modifying classical interest rate models (two in the Q-measure and two in the P-measure) to use the VAE for dimension reduction.
Each of these models starts with a popular classical model, and then its state variables are replaced with autoencoder latent variables.
Download the paper below to learn about the AEMM methodology in more detail.
CompatibL’s Autoencoder Market Models are open source and are freely available to the capital markets community. Please contact us and we will guide you through how to best implement the models in your particular case.
Interested in Learning More?
Read our latest article on the future of interest rate modeling and watch Alexander Sokol’s interview with WatersTechnology on how to enhance traditional interest rate pricing and risk models with machine learning.


